
[Q&A no.12] Crawlowanie i indeksowanie strony/ Łukasz Rogala
Q&A4 kwietnia 2019
12-sta odsłona cyklu Q&A w naszej Bazie Wiedzy. Ostatnim poruszanym tematem był Mobile-First Index.
W tej części zajęliśmy się tematem crawlowania i indeksowania strony. Na pytania związane z poprawą tzw. crawl budżet, w tym tematem analizy logów serwera i danych dostępnych w innych narzędziach analitycznych odpowiedział Łukasz Rogala - Head of SEO w Loando.pl, specjalista od całościowej strategii organicznej obecności firm w Google.
1. Jakich narzędzi używasz do analizy logów serwera?
W zależności od wielkości strony – a tym samym ilości logów – pracuję albo na dedykowanych rozwiązaniach/rozbudowanych SaaSach (Logz.io/Splunk/OnCrawl). Na potrzeby prostej analizy (logi z jednego, dwóch dni) – Screaming Frog Log File Analyzer. Wymaga nieco więcej zasobów, ale rekompensuje to niższą ceną (licencja dostępna na rok).
2. Jak interpretujesz dane z logów serwera i jak je wdrażasz w życie?
Zawsze sięgam do logów serwera żeby lepiej zrozumieć faktyczne zachowanie robotów na stronie. Niestety Screaming Frog czy inny crawler zewnętrzny jedynie imituje zachowanie Google, a jak wiemy w praktyce robot czasami trafia do najmniej oczywistych zasobów i próbuje je zaindeksować.
Kluczowa jest dla mnie ilość eventów jakie mają miejsce w logach. Jeżeli widzę że robot Google lub jakiś podejrzany User Agent wywołuje wyjątkowo dużo akcji – sprawdzam dokładnie co to są za podstrony i dlaczego poświęca im tyle czasu.
Na podstawie logów tworzę sobie „mapę witryny” na podstawie której mogę porównać:
- Stopień zaindeksowania witryny w Google (czyli ile wyników mogę wyciągnąć z indeksu vs po ilu robot Google faktycznie chodzi)
- Ile linków znajdują zewnętrzne crawlery
- Jakie są różnice czyli ile contentu faktycznie produkujemy, a ile podstron było kiedykolwiek odwiedzonych przez robota Google?
- Czy w logach pojawiają się jakieś nadprogramowe błędy i przekierowania, których nie wykrył zwykły crawler?
Wdrożenie rekomendacji to zazwyczaj praca ramie w ramię z developerem. Zebrane dane dokładnie omawiam w formie tasku i dopasowuję na tej podstawie rekomendacje w zależności od problemu z jakim walczymy.
Przykładowo - pomimo ustawienia 404 na określonych podstronach robot Google nadal do nich dociera i próbuje je indeksować. W związku z tym jeżeli wiemy, że nigdy więcej nic na nich nie będzie – w to miejsce wdrażamy odpowiednie przekierowania 301 lub zmieniamy kod odpowiedzi serwera na 410.
3. Jak sprawić, by robot Google podążał po tych zasobach, na których nam najbardziej zależy?
Zazwyczaj efekt ten osiągamy dbając o dobrą optymalizację linkowania wewnętrznego (maksymalne crawlability strony), a także odpowiednie linkowanie z zewnątrz do interesujących nas zasobów (w myśl zasady, że skoro ten content ma zapewniać ruch to warto go odpowiednio podlinkować). Czasami jednak trzeba podejść do problemu z drugiej strony – pozbyć się tych podstron, które jedynie „zaśmiecają” nasz indeks.
4. Jak sprawdzić czy strona w JS crawlowana i indeksowana jest poprawnie?
Przede wszystkim należy pamiętać o tym, że strony mocno opierające się o JS są renderowane rzadziej. Google pomimo ogromnej ilości zasobów nie ma ich na tyle by renderować i indeksować stronę on demand stąd bardzo często opóźnienia w tym co Google widzi vs tym co widzimy my.
Dane o crawlowaniu znajdziemy w logach serwerowych lub jeszcze przez jakiś czas w starym Google Search Console. Warto także postawić na sprawdzenie tego w Screaming Frogu aktywując odpowiednią funkcję w ustawieniach narzędzia:
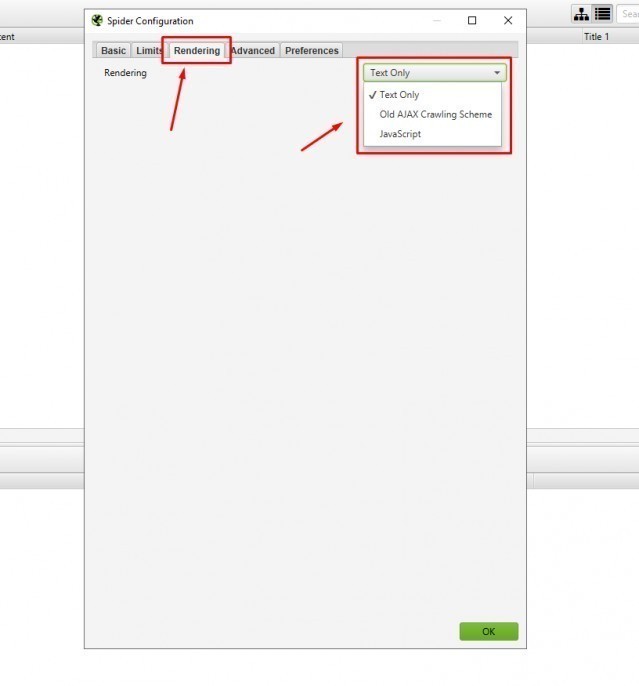
Stopień zaindeksowania zwyczajowo możemy sprawdzić używając komendy site: + słowa kluczowego, na które chcemy aby dana podstrona pozycjonowała się w Google.
W przypadku problemów z crawlowaniem warto upewnić się jak Google renderuje stronę oraz czy widzi kod HTML korzystając z odpowiedniej opcji w Google Search Console lub w testerze mobilnym:
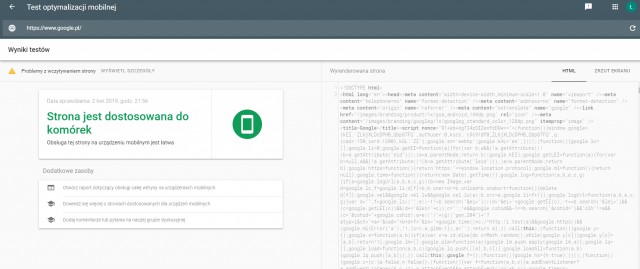
Ważne: Można jeszcze odpalić Chrome 41 i tam zobaczyć czy wszystko wyświetla się poprawnie. Jeżeli nie – należy domniemywać, że Google także będzie miało z tym problem.
5. Czy indeksowanie wyników wyszukiwarki wewnętrznej kiedykolwiek ma sens w przypadku e-commerce?
Ma to sens wtedy i tylko wtedy, gdy są zasoby do monitorowania, optymalizowania uzyskanych wyników i ciągłego kontrolowania tego co indeksować i dlaczego. Wymaga to także odpowiedniego zarządzania literówkami.
Znam przypadki skutecznego budowania ruchu organicznego na wynikach wyszukiwania – niestety zazwyczaj „Internal Searchem” zajmują się tym dedykowane osoby, blisko współpracujące ze specjalistą SEO. W centralnie zarządzanych biznesach (międzynarodowych), gdzie centrala decyduje o wdrożeniach lokalnie – niejednokrotnie dobrze rozegrane zarządzanie wewnętrzną wyszukiwarką pozwala realizować ponadprzeciętne cele biznesowe.
W przeciwnym razie – lepiej postawić na statyczną strukturę podstron, tworzoną wtedy i tylko wtedy, gdy jest za tym uzasadnienie biznesowo/organiczne.
6. Google zaindeksowało moją stronę tylko częściowo, z 29 tys przesłanych linków tylko 7 tys. Stan ten nie zmienia się przez długi okres, linki to różne produkty. Jak w takim razie przyspieszyć indeksowanie tych stron? Bardziej ogólnie - jak przyspieszyć/wznowić proces indeksowania dla stron, które zostały zaindeksowane tylko częściowo?
Ciekawy przypadek – czy produkty są do siebie podobne/różnią się tylko atrybutami i niczym więcej?
Jeżeli tak to warto zastanowić się nad przebudowaniem serwisu tak, że będzie produkt – matka, a wszelkie jego odmiany będą kanonicznie (rel=”canonical”) wskazywać na niego. Jeżeli jednak występuje duża różnica, to sprawdziłbym w logach serwerowych czy i jak często odwiedza je robot Google oraz popracowałbym nad linkowaniem wewnętrznym. Warto zastanowić się nad podzieleniem sekcji marketing automation (powiązane produkty) na taką stricte remarketingową oraz „seową” – czyli crosslinkowanie pomiędzy produktami tego samego typu. Zwiększając w ten sposób dotarcie powinniśmy poprawić skuteczność indeksowania podstron w Google. Pomocne będzie także pozyskiwanie linków do strony kategorii, w której znajdują się produkty.
7. Czy googlebot przechodzi po menu zrobionym z selectów, a konkretniej z select2 (select2.org) w jquery? Mam tak zrobione menu i wartości typu: < option value="strona-docelowa" data url="https://www.strona.pl/stron...">Anchor text < /option > Jeżeli odpowiedź będzie, że crawluje takie menu i opcje, to czy jest sens zmieniać takie menu na czysty HTML? Uzyskam tutaj jakąś korzyść?
Jest szansa, że Google wyłuska sobie ten adres URL i będzie próbować go indeksować ALE podczas ostatniego I/O w 2018 roku Google pokazało przykłady dobrze zrobionych linków wewnętrznych, po których robot na pewno pójdzie (nie daje to gwarancji zaindeksowania, ale na pewno zwiększa crawlability):
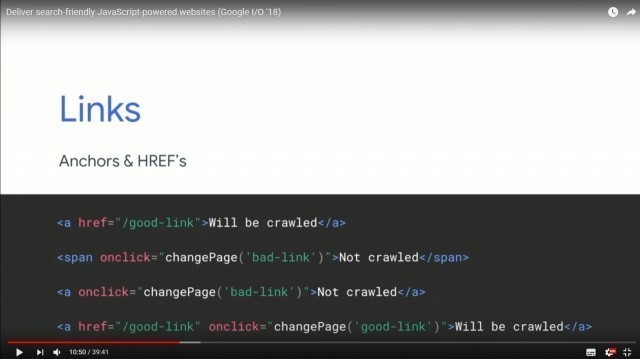
Dla świętego spokoju przepisałbym to tak jak należy. Mniejsze ryzyko, że coś pójdzie nie tak w przyszłości.
8. Jaka jest różnica między crawlowaniem i indeksowaniem?
Crawlowanie – czyli proces przechodzenia po linkach wewnętrznych i zewnętrznych w celu zbudowania „mapy” strony. Indeksowanie to fakt umieszczenia strony w indeksie Google, czyli uczynienie jej „dostępną do wyszukania”.
9. Czy za rozmiar crawl budżetu odpowiadają tylko linki i poprawność techniczna strony?
Dla większości stron Google zaleca nie przejmować się crawl budgetem:
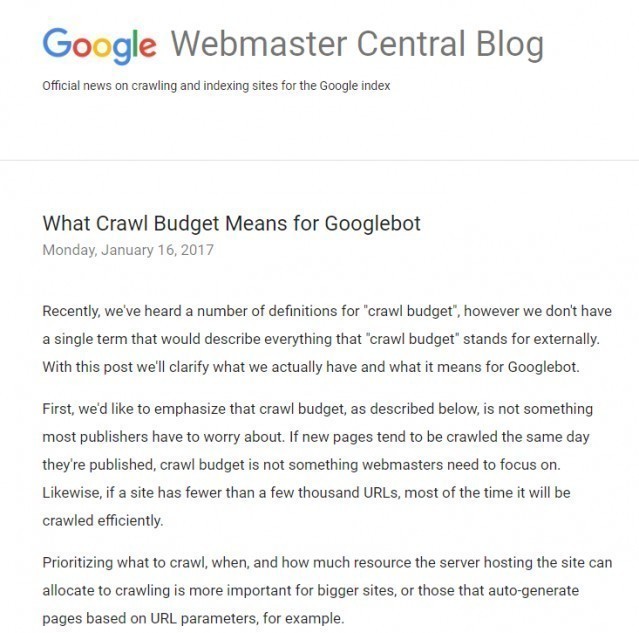
Link do pełnego wpisu: https://webmasters.googleblog.com/2017/01/what-crawl-budget-means-for-googlebot.html. Zaryzykuję stwierdzenie, że duży może więcej – i bardzo często duże, uznane marki (sporo wzmianek, sporo zapytań brandowych) mogą sobie pozwolić na więcej SEO „fakapów” niż mniejsi zawodnicy. Przykład?
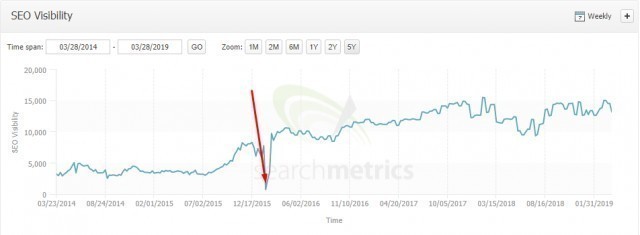
Potężny redesign, strona częściowo zbudowana w Java Script i tajemniczy noindex na escaped fragmencie. Udało się go szybko namierzyć, jednak deploy chwilę musiał poczekać. Pomimo spadku strony do niemal 0 w indeksie – szybko wróciła na swoje miejsce (rozsądnie podlikowana, bardzo dobra pod względem optymalizacji).
Natomiast nie jest to zero – jedynkowe. Są sytuacje w których słabo zbudowana strona indeksuje się szybciej bo ma dużo linków zewnętrznych (spore uznanie, duży trust flow) – a są takie strony, które bez dużej ilości linków generują maksymalne crawlability.
10. Jak poprawić crawlowanie i indeksowanie strony na joomli?
Zmiana CMSa na inny (niekoniecznie Wordpress) ; ) . A na serio – sporo zależy od konkretnego przypadku. Joomla ma to do siebie, że potrafi generować bardzo duży śmietnik w indeksie ze względu na swoją konstrukcję. Dlatego pierwsza rzecz jaką należy zrobić to site:domena.pl i ręczny (lub automatyczny) przegląd tego co już w indeksie się znajduje i dlaczego. Potem sukcesywne porządkowanie, usuwanie, blokowanie indeksacji – połączone ze zmianami on-site (zwłaszcza w kontekście linkowania wewnętrznego).
11. Stworzyłem ostatnio sitemapę ściągniętym na dysk programem. Pełna zawierała 15.000+ URL-i i 4000+ błędów, ale narzędzie do jej tworzenia nie wygenerowało mi jej. Cały proces trwał 1,5 doby. Wiele stron było duplikatami typu: www.surebety.pl (kanoniczna), www.surebety.pl/artykul/bukmacherzy-dla-polakow?page=2#last_comment (duplikat), www.surebety.pl/wyniki-wyszukiwania?q=ranking (duplikat). Potem znalazłem lepsze, darmowe narzędzie bez limitu stron i z wieloma parametrami, m.in. wykluczeń, i wyszło ok. 1000 adresów, które udało się obciąć do ~360 bez duplikatów wyżej wymienionych.
- Czy w sitemapie powinienem jakoś oznaczać te duplikaty? Podejrzewam, że robot google dobrze sobie radzi z rozróżnianiem stron kanonicznych od tych z parametrem typu "?" i nie ma potrzeby zwiększać rozmiaru sitemapy, operując wykluczeniami tych stron duplikatów z pliku robots.txt.
- Czy warto dodać do indeksacji najważniejsze wyniki wyszukiwań pod "wartościowe" frazy?
- W pliku robots.txt chciałbym generalnie wykluczyć indeksowanie użytkowników, ale dopuścić wyjątki - żeby indeksowało najbardziej znanych użytkowników. Jak to ustawić? Wytyczne google nie odpowiadają na moje pytanie: https://support.google.com/webmasters/answer/6062596?hl=pl
- Jakie polecacie narzędzia do utworzenia/skonfigurowania statycznych image-sitemap, video-sitemap? Znalazłem jedno, ale muszę najpierw usunąć błędy walidacji żeby zadziałało : )
- Mam na stronie filmiki z YouTube, które sam tam umieściłem. Są częścią artykułu, ale są hostowane z YouTube, a więc są de facto zewnętrzną częścią mojego serwisu. Nie mam innych filmików hostowanych z mojego serwera. Czy powinienem tworzyć video-sitemap?
- Z tego co wiem, to parametr < priority > już nie ma znaczenia w sitemapach. Czy w takim razie nie lepiej wstawiać lekką sitemapę TXT zamiast XML, skoro przekażą te same treści (z wyjątkiem ostatniej aktualizacji, która nie ma większego znaczenia)?
Zacznę żartobliwie, bo to bardzo kompleksowe pytanie:

A na serio:
- To co znajduje się po # jest dla Google nieindeksowalne – w sensie może wyświetlić się jako kotwica w meta description – ale nie musi.
- W sitemap.xml dajemy unikalne adresy. Nie dajemy żadnych duplikatów, adresów które wskazują kanonicznie na inne, są zablokowane przed indeksowaniem itd. Generuje to spory śmietnik w GSC i podnosi ciśnienie za każdym razem kiedy otwieramy skrzynkę mailową – bo Google będzie „krzyczeć” że to źle.
- Kwestia indeksowania wyników wyszukiwania to temat rzeka – tak długo jak jest nad tym kontrola (poprawa literówek, unikanie duplikatów pomiędzy stronami statycznymi, linkowanie wewnętrzne) – warto to robić. W przeciwnym wypadku lepiej tego unikać.
- Wydaje mi się, że w przypadku selektywnego indeksowania lepiej postawić na stosowanie noindex, follow zamiast zabawę w robots.txt. Jeżeli jednak ma być to zrobione poprawnie to trzeba będzie zrobić listę typerów którzy będą allow i umieścić ją w pliku robots.txt, a po niej dodać Disallow: /typerzy/*.
- Do ImageSitemap wystarczy Screaming Frog ALE dużo lepiej sprawdzi się rozwiązanie developera żeby sitemap.xml aktualizowało się za każdym razem jak dojdzie lub zostanie usunięty content.
- Nie robiłbym video sitemap w tej sytuacji. Zadbałbym o dobre schema video wszędzie tam gdzie mamy jakiś filmik osadzony na naszej stronie.
- Nigdy się nad tym nie zastanawiałem, bo koszt wygenerowania sitemap.xml jest zawsze relatywnie niski i do zrobienia „od ręki”; ) . Ale jest to coś wartego przetestowania dla freaków wydajności na każdym poziomie.
12. Co wziąć pod uwagę w audycie crawl budget?
Przede wszystkim to, czy ilość podstron w logach zgadza się z ilością podstron w indeksie, w pliku sitemap.xml, oraz w zewnętrznych crawlerach. Druga rzecz to kody odpowiedzi serwera oraz stosunek zapytań mobilnych do desktopowych.
Potem mając już te informacje – pracujemy nad optymalizacją strony.
13. Jak na przestrzeni ostatnich lat zmienił się sposób crawlowania witryn przez Google?
Przede wszystkim zmieniły się same strony co wymusza na Google nieco większego sprytu niż wcześniej. Niestety jesteśmy świadkami rozwoju JS co także wymusza na Google konieczność dostosowania się.
Google jest przede wszystkim bardziej agresywne mobilnie. W logach dominują zapytania związane z wersją mobilną strony.
Jednocześnie jest BARDZO wyczulone na low quality/near duplicate content. W rezultacie jesteśmy świadkami coraz częstszego ignorowania sugestii typu rel=”canonical” lub porzucenia znaczników rel=”prev”/rev=”next”.
Pomimo mobilnej agresji – da się odczuć „sufit technologiczny” Google. Nie wszystkie strony dostają się do indeksu, proces aktualizacji wyników wyszukiwania zwalnia. Google pod płaszczykiem „troski o wygodę użytkownika” powoli dąży do ograniczenia zasobów wydawanych na crawlowanie. Co to znaczy dla webmasterów? Większe wydatki w Google Ads.
 Łukasz Rogala
Łukasz Rogala