
Co to jest i do czego służy plik Robots.txt
Artykuły19 lutego 2021
Wstęp
Boty (inne określenia roboty, crawlery) powstały po to, aby przemierzać bezkresy internetu zbierając dane o stronach internetowych, ich strukturze itd., na przykład po to, żeby spamerzy zebrali dostępne adresy e-mail do wysyłki spamu. Wyszukiwarki treści jak Google, Bing również wysyłają swoje boty, ale w celu indeksowania i aktualizowania danych dostępnych w ich usłudze. W 1994 roku powstał protokół odnoszący się do kwestii z tym związanych (eng. Robots Exclusion Protocol).

Co to jest robots.txt?
Rola pliku robots.txt to swego rodzaju instrukcja obsługi danej strony, nie dla użytkowników, a dla botów. Niczym tablica ogłoszeniowa informuje, które boty mają wstęp, a które nie mają, lub czy mają ograniczony dostęp. Plik robots.txt, umieszczony w głównym katalogu strony (eng. Root directory) służy do wykluczenia botów z „przeglądania” strony internetowej lub jej części (stron, kategorii, obrazów lub innych elementów UX). Ponadto możesz umieścić tam adres do mapy strony.
Jak stworzyć plik robots.txt
Choć własnoręczne stworzenie pliku robots.txt jest proste, do dyspozycji masz także darmowy generator, ale wciąż warto wiedzieć co oznaczają poszczególne linijki kodu. Wszystko sprowadza się do tego, że najpierw określasz kto jest adresatem komunikatu (User-Agent), a potem formułujesz ogłoszenie za pomocą polecenia „Allow” (zezwalasz na wstęp) lub „Disallow” (brak wstępu). Są też inne polecenia, ale o tym później.
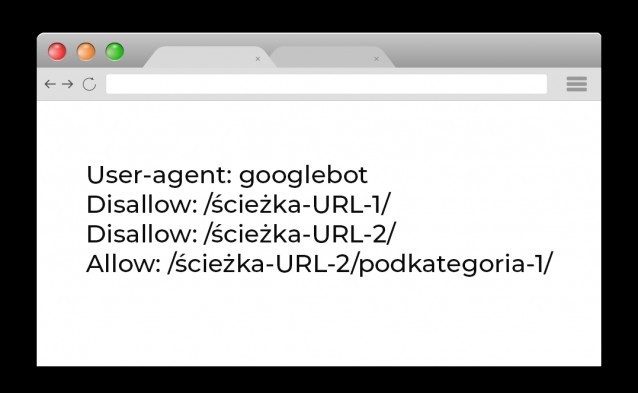
Jakie boty odwiedzają plik robots.txt
Najbardziej interesujący odbiorcy pliku robots.txt to boty indeksujące wyszukiwarek internetowych. Najpopularniejsza z nich, Google, poza głównym robotem, ma jeszcze inne, które mają bardziej precyzyjne zadania (obrazki, wiadomości, wideo). Lista poniżej:
- Google: Googlebot
- Google Images: Googlebot-Image
- Bing: Bingbot
- Yahoo: Slurp
- Yandex: YandexBot
- Baidu: Baiduspider
- DuckDuckGo: DuckDuckBot
Bardziej szczegółowa lista crawlerów przemierzających internet znajdziesz w artykule na stronie Webnots.

Komunikacja z botami
Jeśli nie chcesz adresować komunikatu do konkretnego bota, umieść znak „*”, to znaczy, że informacja jest skierowana do wszystkich zainteresowanych (poza adsbotami, które sprawdzisz na liście Google, te musisz zawsze przywołać z nazwy). W komunikacie należy zawrzeć przynajmniej jedną komendę z dostępnych. Choć są inne polecenia poza zezwolenie i zabronieniem wejścia na stronę, to te są najczęściej używane.
Zacznę od „Disallow”, ponieważ to jest funkcja do blokowania całych podstron, które uznajemy za zbędne do crawlowania. Zezwolenie na wejście na strony (bez wymaganego loginu i hasła) jest domyślne dla botów, ale komenda „Allow” przydaje się np. w kombinacji z „Disallow”, gdy cała kategoria ma być wykluczona, ale jedna z podstron ma być otwarta. Znak „/” oznacza całą domenę, a jeśli podasz konkretną ścieżkę URL, pamiętaj, że wykluczenie dotyczy również dalszych podstron.

Robots.txt odniesieniu do SEO
Podejrzewam, że interesuje cię przede wszystkim wątek o pliku robots.txt związany z SEO. Otóż protokół „Robots Exclusion Protocol” był łatwym sposobem na zablokowanie indeksowania dużej liczby stron z wyszukiwarki Google. Choć oficjalnie Google nigdy nie wspierało komend noindex, nofollow i crawl-delay w pliku robots.txt, faktycznie można był to spokojnie wykorzystywać, ale ostatecznie zgodnie z komunikatem z września 2019 taka sytuacja nie ma już miejsca.
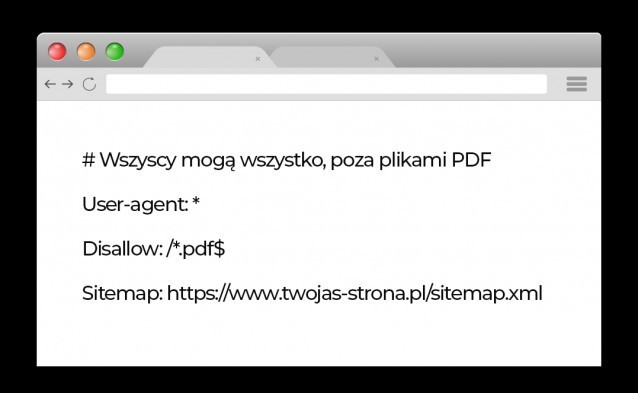
Komendami „Allow” i „Disallow” wykonasz wszelkie kombinacje jakie potrzebujesz. Wykluczysz ścieżki URL, które nie mają wartości dla botów (czyli zoptymalizujesz swój crawl budget), usprawniając ich pracę. Konkretnie oprócz wykluczenia całych katalogów podstron możesz np.:
- Zabronić dostępu tylko 1 botowi
- Zabronić dostęp wszystkim oprócz 1 bota
- Wykluczyć obraz z Grafiki Google blokując crawlera Google-Image
- Zdefiniować typ pliku, który chcemy, aby pomijano*
* Poza symbolem „*” do oznaczenia ogólnej dostępności dla wszystkich botów, jest jeszcze znak „$” i „#”. Pierwszy z nich użyty na końcu ścieżki URL oznacza koniec adresu, a drugi określa linie tekstu jako komentarz, którego boty nie biorą pod uwagę.
Więcej informacji o robots.txt
Co jeszcze warto wiedzieć o robots.txt przygotowałem w formie krótkiej listy:
- Robots.txt nie jest niezbędny, brak pliku dla botów oznacza tyle co „User-Agent: *”, „Allow: / ”.
- Bot od Google zwraca uwagę polecenia pliku robots.txt, ale to nie znaczy, że każdy bot tak robi
- Użycie komendy „disallow” w pliku robots.txt nie oznacza braku indeksacji danej strony, np. googlebot może dotrzeć do niej przez inne linki (skorzystaj z metatagu albo nagłówka HTTP X-Robots-Tag)
- Jeśli korzystasz z Google Search Console, masz do dyspozycji tester pliku Robots.txt
- W wypadku sprzecznych komend, Google wybierze to zezwalające (Bing też, inne prawdopodobnie wybiorą pierwsze w kolejności)
- Jeśli masz subdomenę, stwórz osobny plik robots.txt i umieść go w głównym folderze subdomeny
- Zwracając się do konkretnego bota umieść wszystkie polecenia w jednym wątku
- Zwracając się zarówno do wszystkich botów, jak i wyszczególniając konkretny, pamiętaj że ten konkretny weźmie pod uwagę tylko polecenia skierowane do niego, a te ogólne pominie
- Duże i małe litery mają znaczenie
- Format text/html pliku robots.txt nie jest konieczny, ważne żeby treść się zgadzała z wytycznymi Robots Exclusion Protocol
- Maksymalna wielkość pliku to około 500kb
Podsumowanie
Plik robots.txt to pozornie mało istotny element SEO, ale zwyczajna pomyłka, drobny błąd lub zaledwie literówka może narobić wiele szkód. Warto go mieć na uwadze nie tylko podczas audytu SEO, ale również wykluczając nieistotne strony.
https://www.webnots.com/user-agents-list-for-google-bing-baidu-and-yandex-search-engines/
https://developers.google.com/search/docs/advanced/robots/create-robots-txt?hl=pl&visit_id=637489372261399868-2242120257&rd=1
https://www.deepcrawl.com/blog/best-practice/common-robots-txt-mistakes/
 Paweł Białas
Paweł Białas