
Jak działają crawlery Google?
Artykuły10 maja 2022
Jak działają crawlery Google?
Dobra strona internetowa – czyli taka, która pozwala docierać do pożądanych odbiorców i zyskiwać duże zasięgi – musi być przygotowana nie tylko „pod użytkownika”, ale także z myślą o robotach wyszukiwarek. To konieczne, aby dobrze się indeksowała i mogła osiągnąć wysoką pozycję w SERP-ach. Czym są crawlery Google, bo o nich mowa, i jak działają? Wyjaśniamy.
Crawlery Google – co to jest?
Crawlery Google to inaczej roboty/boty indeksujące, czyli specjalne programy, których zadanie polega na zbieraniu danych o strukturze stron zamieszczonych w przestrzeni on-line. W polu zainteresowania takich botów leżą przede wszystkim „dane techniczne”, a zatem np. struktura strony www, jej kod źródłowy, meta tagi, ale również same treści.
Jakie są funkcje web crawlerów Google?
Warto podkreślić, że w systemie Google działa nie jeden crawler, a boty tego typu o różnych celach oraz zadaniach. Jednak w ogólnym ujęciu są one wszystkie przeznaczone do „przeczesania się” przez poszczególne strony www. Mają zweryfikować ich zawartość pod kątem przydatności użytkownikom w konkretnych kontekstach wyszukiwania. Przekłada się to np. na:
- ogólną weryfikację contentu – w tym treści, ale także meta danych czy materiałów multimedialnych,
- sprawdzenie źródłowego kodu serwisu,
- regularne weryfikowanie aktualizacji treści w serwisie – np. tych publikowanych co jakiś czas na blogu,
- sprawdzanie i indeksowanie linkowania wewnętrznego i zewnętrznego do danej strony.
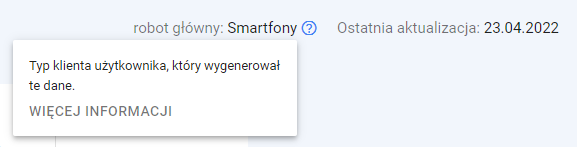
[źródło: Google Search Console]
Strony internetowe są odwiedzane przez wiele różnych robotów Google. Typ klienta, który wysłał żądanie wygenerowania danych, można sprawdzić w statystykach indeksowania.
Fresh crawl, main crawl i deep crawl – czym to się różni?
Wśród botów Google można wyróżnić trzy podstawowe typy programów wykorzystywane do oceny wartości stron pod kątem SEO. Są to roboty, które wykonują:
- fresh crawl – są to regularne i dość częste „wizyty” na indeksowanych stronach w poszukiwaniu ich aktualizacji. Te działania są prowadzone powierzchownie i nie wnikają w głąb struktury serwisu;
- main crawl – jest to bardziej szczegółowy skan, który obejmuje zakładki typu „o firmie”, jak również podstrony z namiarami kontaktowymi. Takie działania są prowadzone mniej więcej raz na tydzień. Taka częstotliwość jest konieczna, aby Google mógł dostarczać użytkownikom aktualnych informacji np. o godzinach otwarcia danej firmy czy numerze telefonu do niej;
- deep crawl – czyli bardzo dogłębne i szczegółowe przyjrzenie się strukturze oraz treściom serwisu, w celu jego poprawnego i rzetelnego zaindeksowania. Ponieważ zadania w tym obrębie wymagają pobrania znacznie większej ilości danych, są realizowane przez boty Google mniej więcej kilka razy w miesiącu.
Wszystkie wymienione powyżej zadania są równie ważne i mają przełożenie na wyniki pozycjonowania. A to pokazuje m.in. jak ważne jest ogólne dostosowanie serwisu pod SEO i jego regularna aktualizacja.
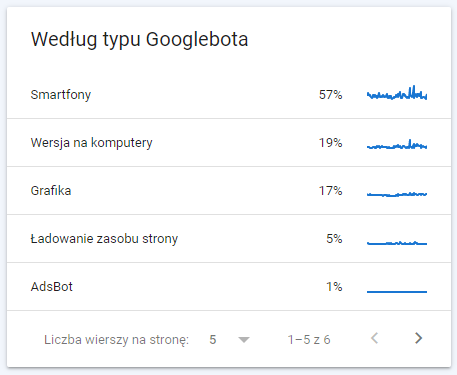
[źródło: Google Search Console]
Google korzysta z co najmniej kilkunastu różnych robotów, które pełnią zróżnicowane funkcje. W danych analitycznych można sprawdzić, które z nich odwiedzają stronę najczęściej i – w razie potrzeby – podjąć decyzję o zablokowaniu którychś z nich.
Jak w praktyce działają crawlery Google?
Zasada działania crawlerów Google, zarówno tych wchodzących głęboko w strukturę serwisu, jak i działających „na powierzchni” jest podobna. Te programy:
- „odwiedzają” indeksowane strony internetowe i analizują je w surowej postaci, a zatem koncentrują się na kodzie źródłowym, CSS, treściach oraz frazach kluczowych,
- wysyłają uzyskane dane do odpowiedniego indeksu – dochodzi tam do rejestracji danych z serwisu oraz ich oceny w kontekście przydatności użytkownikom
Na tej podstawie Google tworzy ranking, który decyduje o kolejności wyświetlania się wyników organicznych po wpisaniu przez użytkownika danego zapytania.
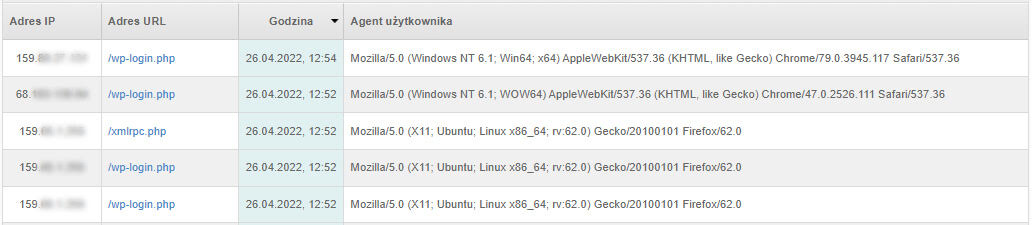
[źródło: fragment logów serwera]
Dane dotyczące „odwiedzin” crawlerów na stronie są dostępne w logach serwera.
Jak dostosować stronę www do wymagań botów Google?
Trzema głównymi elementami, które weryfikują crawlery Google, są:
- treści zamieszczone w poszczególnych zakładkach,
- meta tagi,
- opisy alt do grafik zamieszczonych w serwisie.
Dlatego trzeba zadbać nie tylko o wysoką jakość contentu we wszystkich tych aspektach, ale też i o jego „dobrą komunikację” z botami Google. Chodzi przede wszystkim o:
- prawidłowe zastosowanie słów kluczowych – precyzyjnie dobranych (tak, aby miały odpowiedni potencjał wyszukiwania, a jednocześnie nie „kanibalizowały się” na poszczególnych zakładkach), i użytych z odpowiednią frekwencją oraz precyzją,
- eliminację duplicate content – wszelkie kopie treści, zarówno wewnętrzne (ten sam tekst w kilku zakładkach), jak i z zewnętrznych serwisów są szybko dostrzegane przez crawlery, co prowadzi do obniżenia Page Rank,
- przygotowanie poprawnych tagów meta title i meta description – powinny one zawierać dominujące w danych zakładkach frazy kluczowe, a jednocześnie być czytelne i atrakcyjne dla użytkownika,
- opatrzenie każdego zdjęcia tagiem alt – również dobrze, jeżeli zrobi się to z uwzględnieniem słów kluczowych, ale z zachowaniem rozsądku i wiarygodności.
Warto też pamiętać, że nie wszystkie miejsca na stronie internetowej wymagają częstych wizyt crawlerów. Ruch botów powinien się skupiać na jej najważniejszych (i najbardziej wartościowych dla odbiorców) sekcjach. Nadmierna aktywność mogłaby doprowadzić do przeciążenia serwerów, a z drugiej strony doprowadzić do tego, że Googlebot, z uwagi na ograniczony „crawl budget” pominie ważne aktualizacje. Dlatego warto kontrolować to, do jakich danych będą miały dostęp crawlery i zablokować im możliwość indeksowania zbyt dużej ilości podstron.
Jak zatem widać, dostosowanie strony www do wymagań crawlerów to działania na styku technicznego SEO i pracy nad treścią przystępną dla użytkownika. Tylko połączenie tych dwóch elementów pozwoli sprostać oczekiwaniom botów Google i w konsekwencji wypracować dobre pozycje w SERP-ach.
 Magda Pułym
Magda Pułym